For questions and feedback:
- Project Page: https://jointavbench.github.io
- GitHub: https://github.com/roverx12345/JointAVBench
- Email: chaojh@ruc.edu.cn
Compared to vision or audio large language models (LLMs), the key advantage of omni large language model lies in their joint audio-visual reasoning capability. To train such models, datasets with questions requiring both visual and auditory information to answer are needed. Moreover, videos contain complex audio signal types and scenes, interleaved with each other, demanding models with various cognitive capabilities. However, current datasets lack challenging multi-scene tasks, various types of audio information and cognition abilities.
This paper introduces JointAVBench, a dataset designed to answer questions that necessitate AV integration, spanning 5 cognitive dimensions, 4 audio information types, and 3 scene spans. Our benchmark reveals that the top omni-LLM achieves only 56.2% average accuracy, highlighting significant room for improvement, particularly in cross-scene reasoning.
Our automated benchmark generation pipeline leverages state-of-the-art vision-LLMs, audio-LLMs, and general-purpose LLMs to synthesize questions and answers that strictly require joint audio-visual understanding. The pipeline consists of several stages that ensure high-quality benchmark questions with strict audio-video correlation.
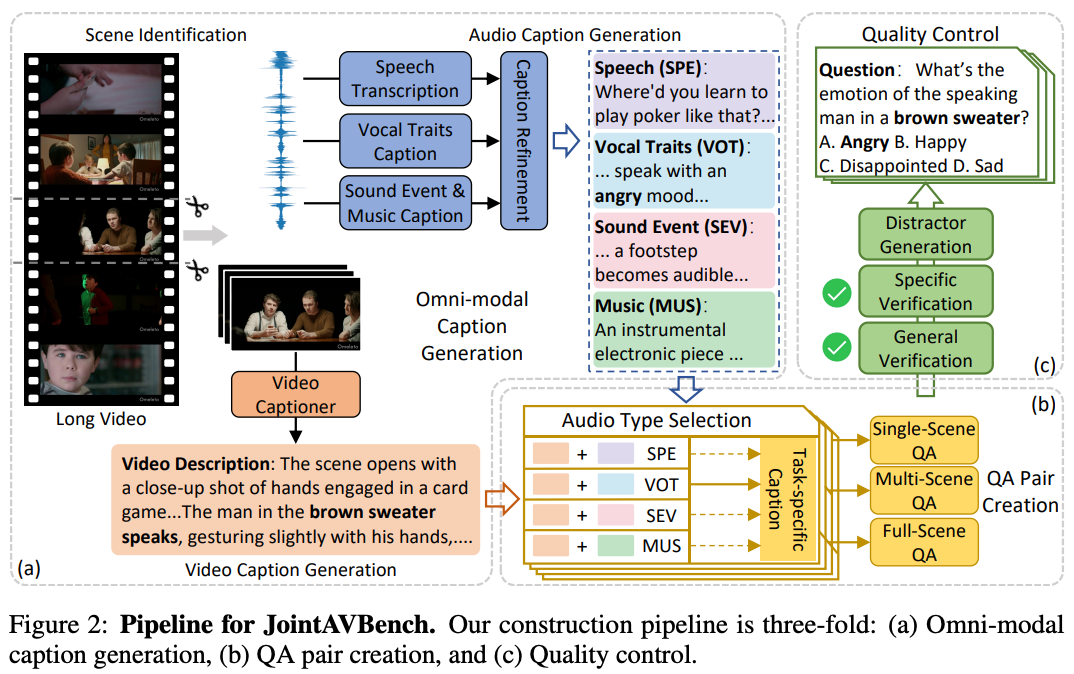
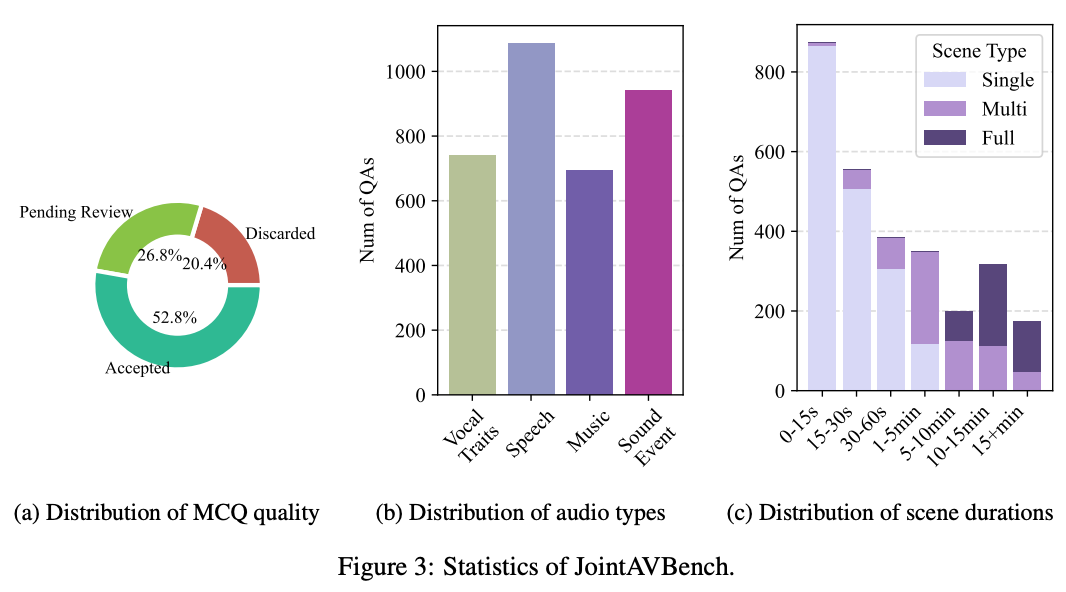
JointAVBench consists of 2,853 questions across 15 distinct tasks spanning multiple dimensions. The benchmark covers diverse cognitive dimensions, audio information types, and scene spans to provide comprehensive evaluation of omni-modal models.
The JointAVBench dataset is available on Hugging Face. The benchmark file jointavbench.json contains all 2,853 questions with metadata. Please note that due to content restrictions, we cannot share the raw videos. However, we provide a URL to the original YouTube video for each question.
# Download benchmark questions and videos
pip install huggingface_hub
huggingface-cli download JointAVBench/JointAVBench --local-dir ./dataEach question in the benchmark follows this format:
{
"qid": "-CEDoGn0w1s_task1_0",
"video_name": "-CEDoGn0w1s",
"task": "STL",
"question": "Which objects are mentioned only in the dialogue...",
"correct_answer": "The broom, mentioned at around 6.34s",
"explanation": "The object \"broom\" is mentioned...",
"options": [...],
"video_url": "https://www.youtube.com/watch?v=-CEDoGn0w1s",
"segment_timestamp": [653.444, 699.657]
}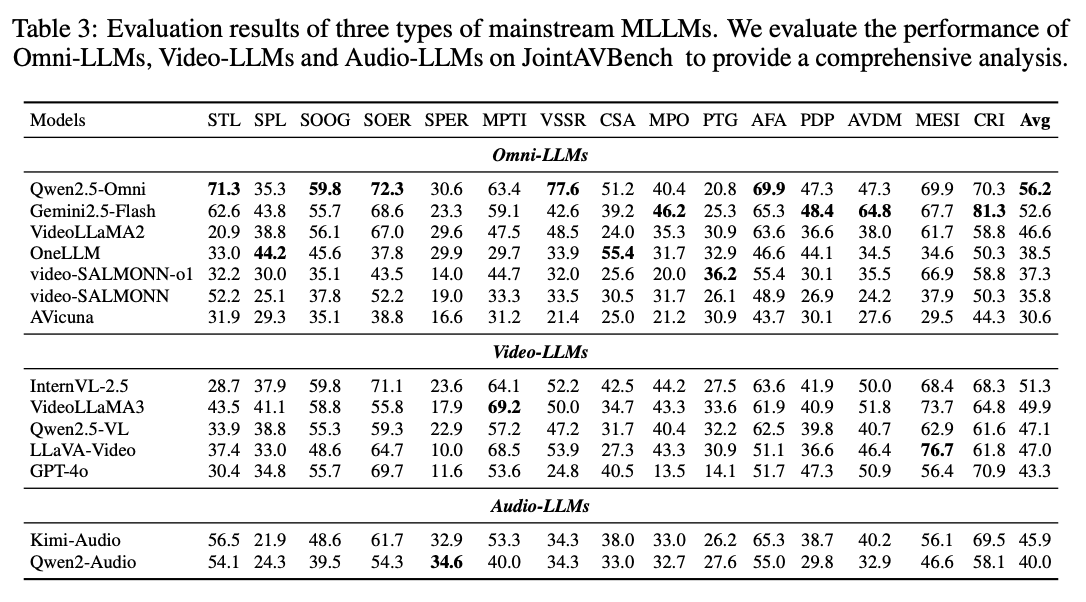
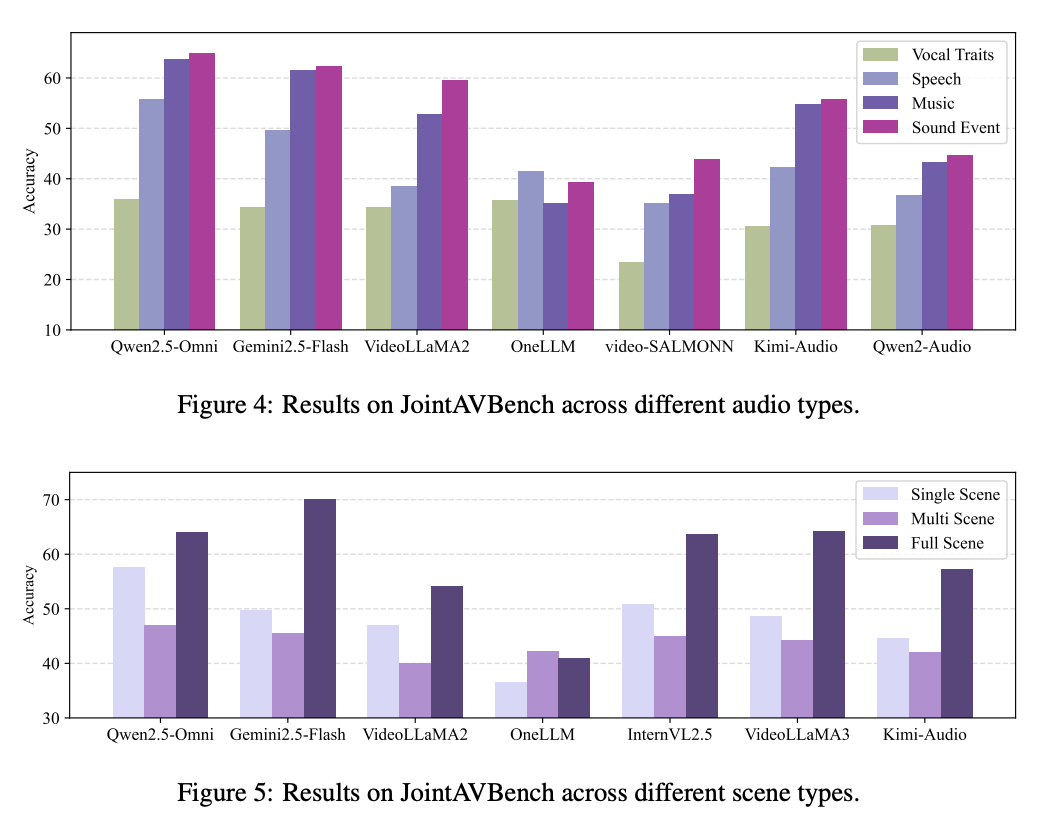
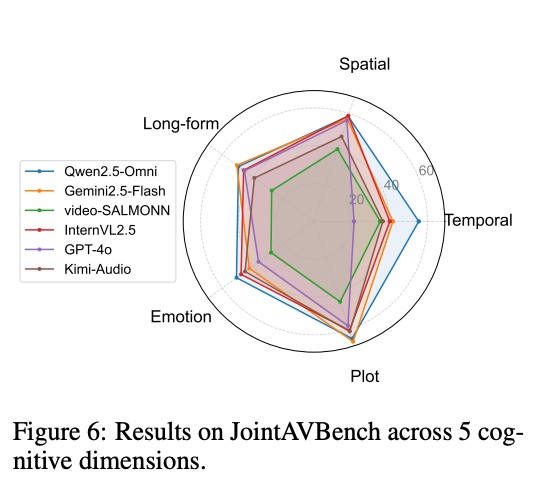
Our benchmark reveals significant challenges for current omni-modal models:
If you find JointAVBench useful for your research, please cite our paper:
@article{chao2025jointavbench,
title={JointAVBench: A Benchmark for Joint Audio-Visual Reasoning Evaluation},
author={Chao, Jianghan and Gao, Jianzhang and Tan, Wenhui and Sun, Yuchong and Song, Ruihua and Ru, Liyun},
journal={arXiv preprint arXiv:2512.12772},
year={2025}
}For questions and feedback: